

¡Hola a todos!. Creo que todos tenemos un concepto de lo que es un «Proceso» y, dependiendo de la disciplina a la que se refiera, puede variar un poco la interpretación del mismo; por ejemplo, en la gestión de calidad, un proceso se mira de una forma distinta a como se mira en informática, específicamente en los sistemas GNU/Linux, se entiende de otra manera. Al final, la informática toma los conceptos del mundo real para «digitalizarlo» en el mundo de los Unos y Ceros. En ésta entrada, hablaremos del concepto de «Procesos» enfocado en los sistemas GNU/Linux, así como también se analizará un poco el comando top.
¿Qué es un proceso?
Es una instancia de un programa en ejecución, también llamado tarea (task) o hilo (thread); En UNIX, un proceso se crea cuando se invoca o ejecuta un programa. Los procesos tienen estados, recursos asociados y pueden coexistir varias instancias de un mismo programa (procesos hijos).
¿Cuál es la diferencia entre un proceso y un programa?
Analogía: Digamos que un Chef quiere hacer un pastel.
- Receta → Programa
- Chef → Procesador
- Ingredientes → Entradas del programa
- Preparación (Actividad) → Proceso

Tomando en cuenta ésta analogía en el mundo de la informática, el programa esta instalado en el SO y no es necesario que este iniciado/ejecutándose todo el tiempo, por eso es una receta; el proceso (Preparación del pastel) aparece cuando se ejecuta el programa, por cuanto tendrá recursos asociados (memoria reservada, consumo de procesador,etc.).
Identificadores
Veamos algunos identificadores que tienen los procesos en los sistemas GNU/Linux:
- Process ID (PID)
- Número único identificador del proceso. El número es importante para gestionar el proceso. Los PID son asignados por el sistema. Se trata de un correlativo, iniciando desde cero, y creciente.
- Parent Process ID (PPID)
- Los procesos a su vez pueden crear sub-procesos (procesos hijos – child process). Un proceso puede tener varios procesos hijo. Un proceso hijo sólo tendrá un padre. El PPID de un proceso es el PID de su proceso padre.
- UID y EUID
- User ID (UID)
- Identifica al creador del proceso (usuario que lo ejecutó). Este usuario y root son los únicos que pueden modificar al proceso.
- Determina si el proceso tiene permiso para acceder a archivos y otros recursos del sistema.
- User ID (UID)
- GID y EGID
- Group ID (GID)
- Igual que el UID pero para grupos de usuarios. Se hereda del proceso padre.
- Effective Group ID (EGID)
- Permite controlar el acceso del proceso a archivos.
- Group ID (GID)
Estados de un proceso
Como se mencionó anteriormente, los procesos tienen un estado que determina cómo se encuentra en ése momento. A continuación, algunos de estos estados:
- R runnable → En ejecución.
- S sleeping → Proceso en ejecución pero sin actividad por el momento, o esperando por algún evento para continuar.
- T sTopped → Proceso detenido totalmente, pero puede ser reiniciado.
- Z zombie → Difunto, proceso que por alguna razón no terminó de manera correcta. No debe haber procesos zombies.
- D uninterruptible sleep → Son procesos generalmente asociados a acciones de IO del sistema.
- X dead → Muerto, proceso terminado pero que sigue apareciendo, igual que los Z no deberían verse nunca.
Finalmente, mencionar que el típico comando para ver el estado de los procesos es ps (Process Status), pero aquí no nos vamos a detener mucho en éste comando. La típica línea de comando que frecuentemente se usa para encontrar un proceso específico es:
ps aux | grep "nombre_proceso"Comando top
Con éste comando, podemos ver todos los procesos en tiempo real (3 segundos de refresco por defecto); es útil y sumamente usado en todos los sistemas GNU/Linux como herramienta de monitoreo, tanto de procesos como de los recursos del sistema:
- Tiempo de actividad y carga del sistema
- Consumo y estados de CPU
- Consumo de memoria física y virtual
Veamos un ejemplo de su ejecución:
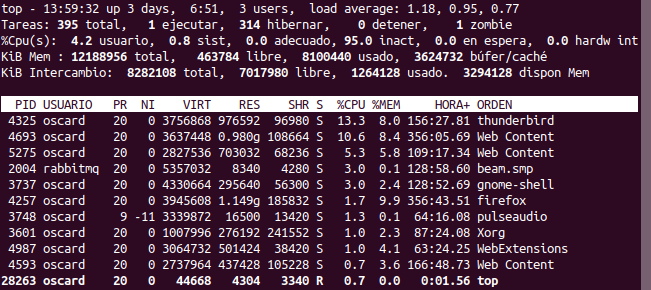
Analicemos un poco cada línea importante:

- Primera línea: Tiempo de actividad y carga media del sistema
- Tiempo de actividad (Tiempo que ha estado encendido el sistema).
Número de usuarios.Load average (Carga media del sistema):- Carga de trabajo que ha tenido el procesador en:
- 1 minuto (Según el ejemplo, valor 1.18)5 minutos (valor 0.95)15 minutos (valor 0.77)
- Carga de trabajo que ha tenido el procesador en:
- Tiempo de actividad (Tiempo que ha estado encendido el sistema).
Con Load Averga hay varios detalles que tenemos que ver, y es que es muy necesario conocer el # de procesadores que se tiene y el # de núcleos por procesador, así para poder tener una mejor comprensión de estos valores, pero espero en una próxima entrada tratar al respecto.

- Segunda línea: Tareas
- Muestra el total de procesos (tareas).Adicional, muestra el número de procesos por agrupación de estado.

- Tercera línea: Estados del CPU
- Muestra los porcentajes de uso del procesador diferenciado por el uso que se le de.

- Cuarta y quinta línea: Memoria física y virtual
- Muestra el consumo de memoria tanto física como virtual (intercambio)
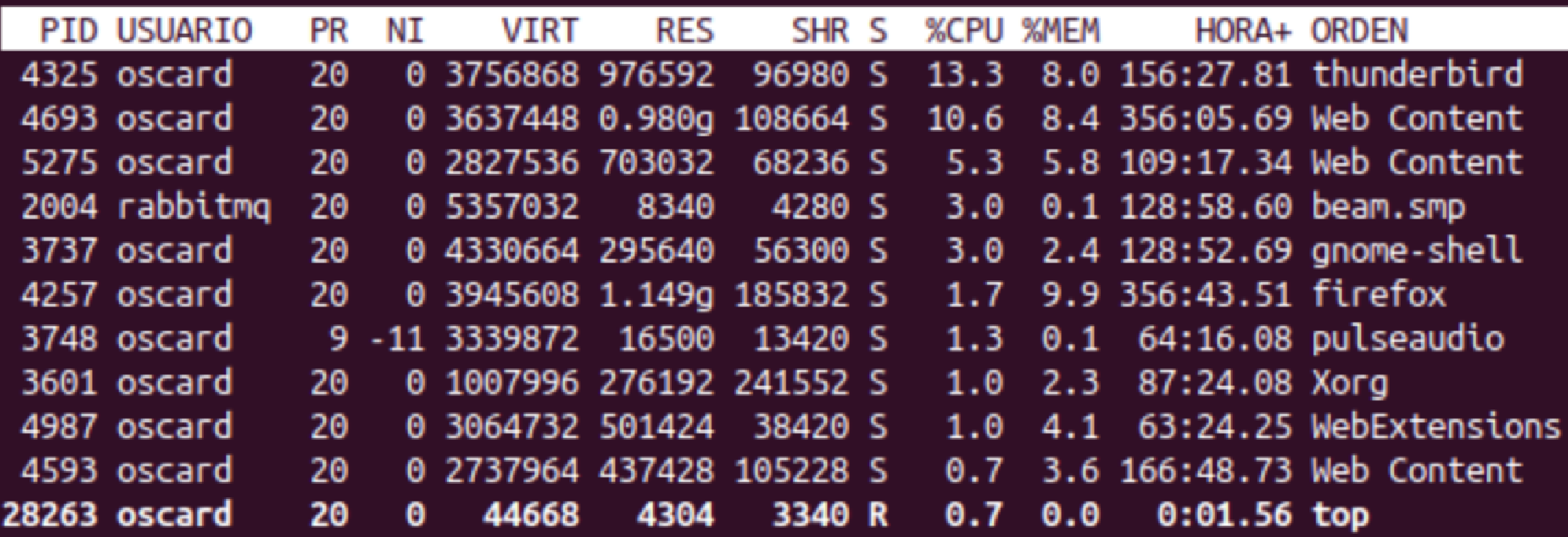
- Columnas: Procesos activos en tiempo real
Otros detalles de top
- Para salirse de top, se debe presionar la tecla [Q]
- Para ver la ayuda de la interfaz top, presionar la tecla [H]
- Para cambiar la escala de medición (digamos, MiB, KiB, GiB, etc.), se debe presionar la tecla [E] para la información de arriba, y [e] para las columnas.
- Para buscar un proceso en específico, se presiona la tecla [L] y se escribe el nombre.
Bien, hay mucho más de lo que se podría hablar del comando top y los procesos, pero nos quedaremos en ésta entrada con ésta información básica.
¡Saludos!
muy importante la administracion de procesos, gracias por compartir !